- Published on
Building an AI Copilot for Salesforce - Part One
- Name
- By Osman Sheikh
- @osmanify
I’ve been itching to build something with AI since OpenAI’s chat models became available via API, both due to a foreboding sense of being left behind as AI takes off and a strong curiosity about what’s currently possible with AI and what’s simply hype.
I learn best by building tangible products, like building a Twitter clone to learn React , and I knew that working on a side project that utilizes Large Language Models (LLMs) would dramatically speed up my rate of learning when it comes to AI.
With that in mind, I decided to build a project that can act as a playground for building with LLMs: an AI Copilot for Salesforce Admins.
Giving an LLM Knowledge of Salesforce
Application metadata declares how the components of an application are set up. For example, Salesforce metadata is data-rich and can be used to migrate or replicate a Salesforce instance just by deploying metadata. Every detail of the Salesforce instance’s objects, fields, automations, and business rules are represented in metadata.
Salesforce’s Tooling API makes retrieving metadata on-the-fly easy. By retrieving the metadata for a component, we can use it to give the LLM contextual knowledge of the admin’s specific Salesforce instance.
This insight is the foundation of my project and every feature I’ve built up to this point relies on using Salesforce metadata to prompt the LLM.
Programmatically Retrieving Metadata
Salesforce's Tooling API works by querying for specific resources via SOQL. To retrieve metadata, we just need the Metadata Type and the ID of the component. Using these parameters, we can construct a query that will return metadata for the specified component.
query_params = {'q': f'SELECT Id, Metadata FROM {metadata_type} WHERE Id=\'{id}\''}
query = f'query/?{urllib.parse.urlencode(query_params)}'
result = sf.toolingexecute(query)
metadata = result['records'][0]['Metadata']
return JSONResponse(content={'metadata': metadata})
We can take advantage of how Salesforce structures URLs to automatically parse the metadata type and ID from the active tab of the user’s browser, allowing us to load the specific component the user is viewing.
const urlParams = new URLSearchParams(url.substring(url.indexOf('?')))
const flowId = urlParams.get('flowId')
Once the metadata is retrieved, it’s formatted to drop empty fields and strip unimportant data like the position of the flow elements. This allows us to reduce token usage when prompting the LLM.
This formatted metadata is then used in various templated prompts and chains to generate content and structured data.
Returning Structured Data
Building this AI copilot, I felt very strongly that chat should not be the only input mechanism. Having the context and metadata set automatically could unlock alternate UX patterns for interacting with the LLM and returning structured data.
To accomplish this, I used Langchain’s Pydnatic parser, along with the OutputFixingParser. The backend server for the copilot is built on FastAPI and I have a decent amount of experience with Pydantic so the choice of tooling here made sense.
Getting the Pydantic parser setup was trivial and, combined with the OutputFixingParser to rerun and fix the prompt when the initial generation does not fit the specified schema, I’ve yet to hit an error from the LLM returning non-schema conforming content.
Meet OpSherpa
The current form of the AI copilot is a Chrome extension with a persistent icon that opens up a sidebar.

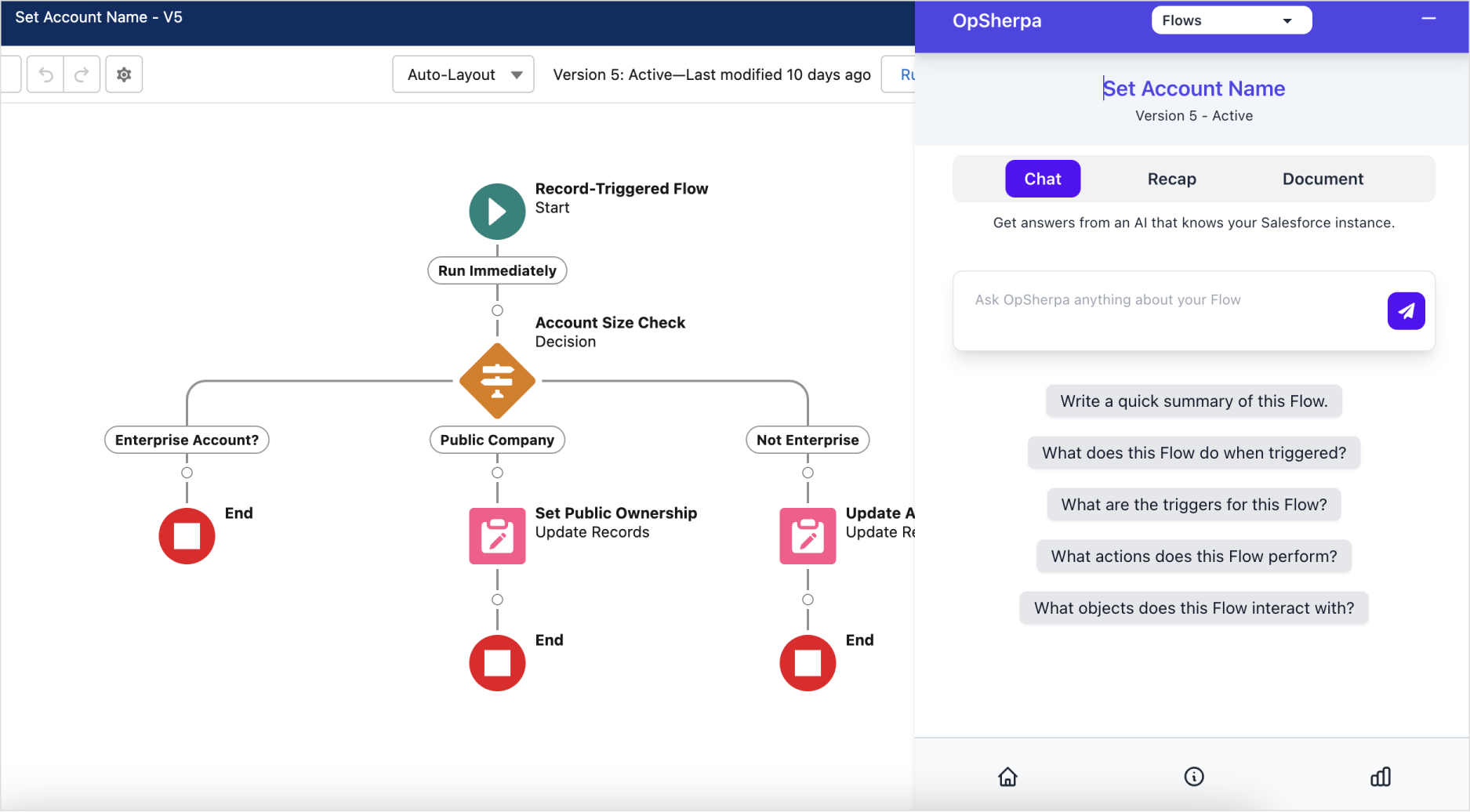
The sidebar is composed of separate "tools" that can be used to interact with the LLM in specific ways.
Recap
The first tool I built in the copilot is Recap, which takes 2 versions of a component and generates a structured comparison of the changes, removals, and additions between versions.

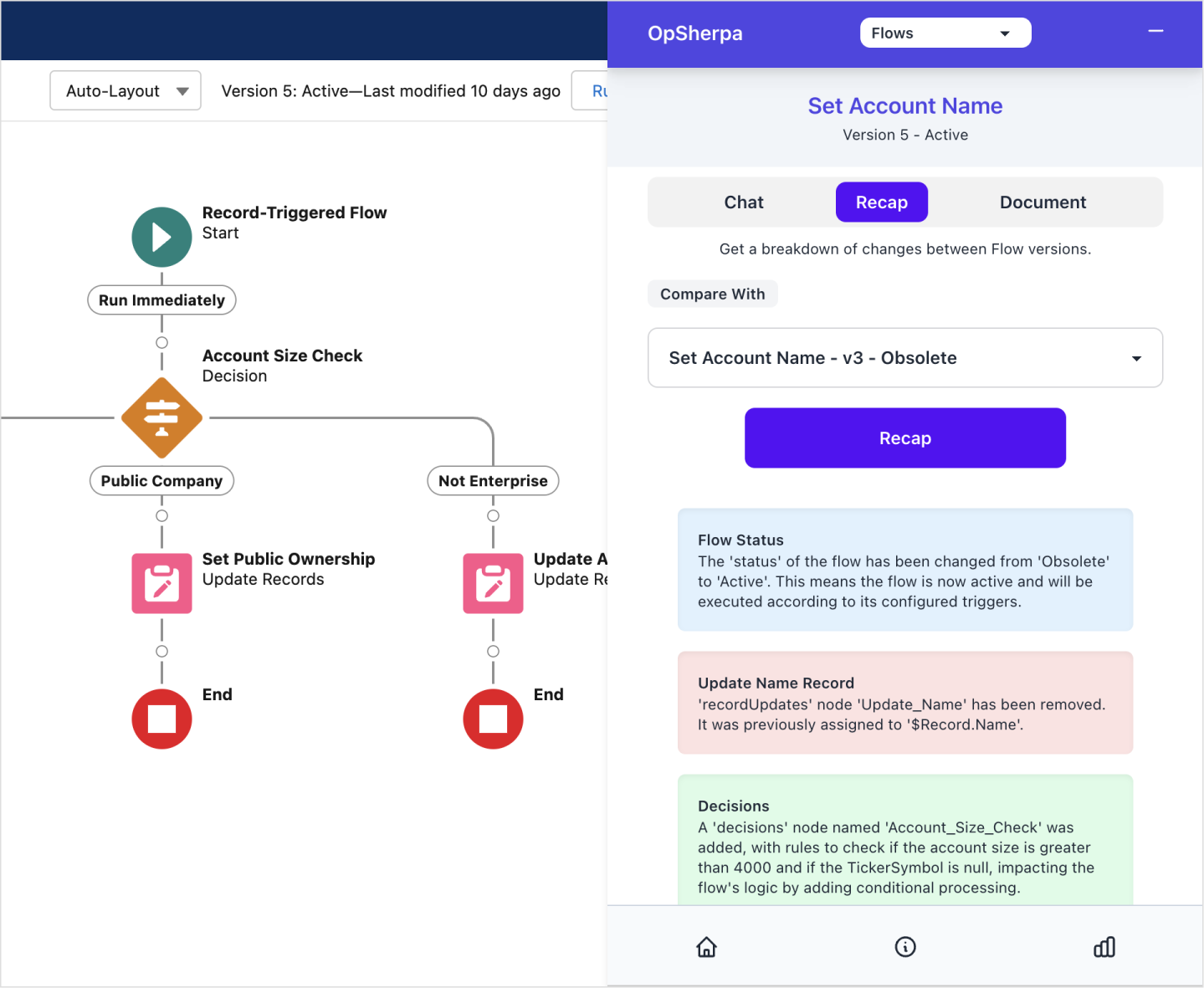
From a functional perspective, this is a very simple tool. It’s a glorified diff tool. But it’s a good example of how the LLM can be used to generate structured data that can be used to power a UI.
This tool is meant to help admins quickly understand how a component has changed between versions and generate a visual representation of the changes.
Chat
Chat may not be the best interface for every interaction with an LLM, but it's a helpful UI for having freeform discussions with the LLM and its context.

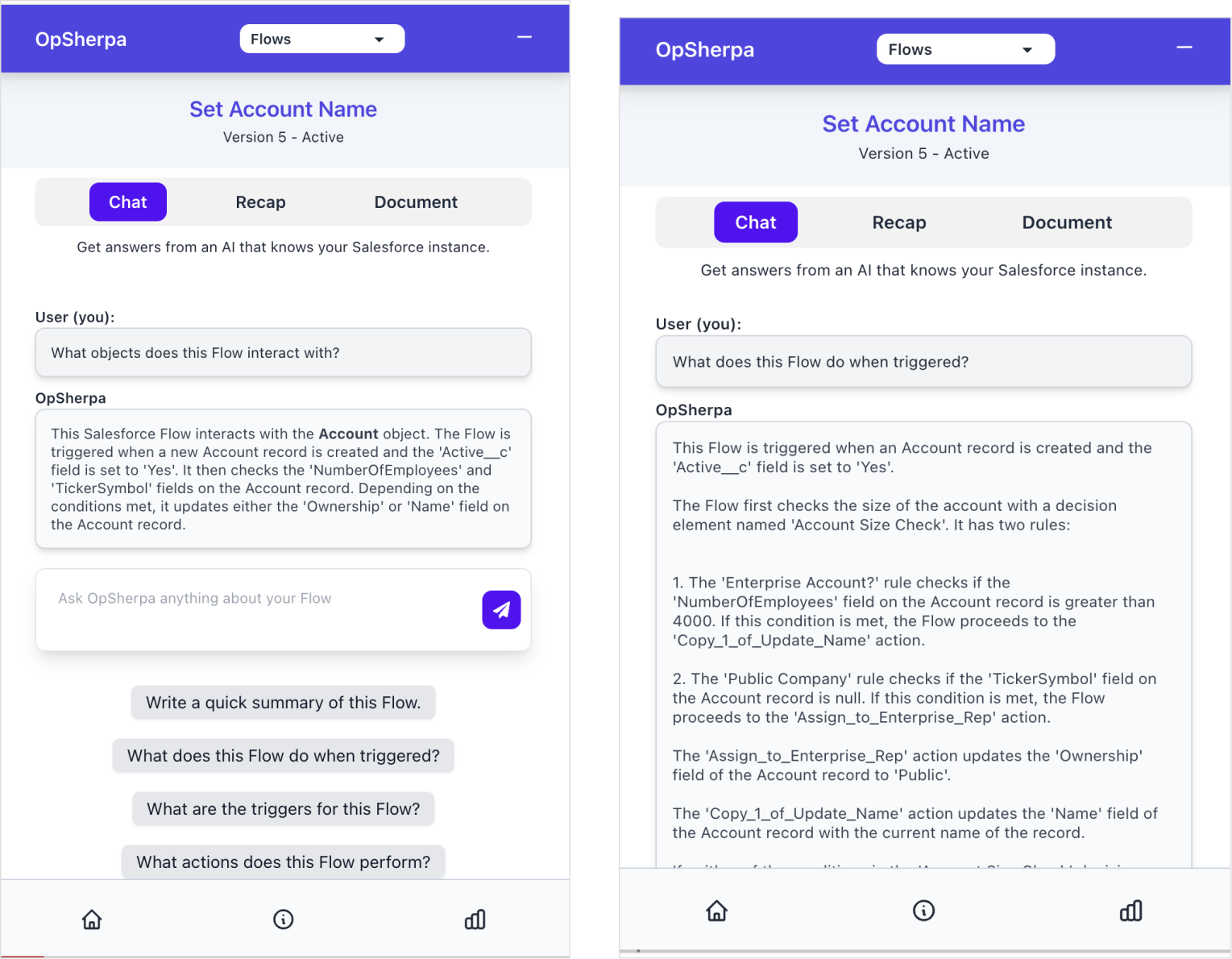
Document
The last tool I built for the copilot is a documentation feature, which generates a document for a component based on its metadata. The documentation is powered by a Pydantic model that serves as the schema for the documentation's table of contents, generating a structured document that can be used to quickly understand the component.

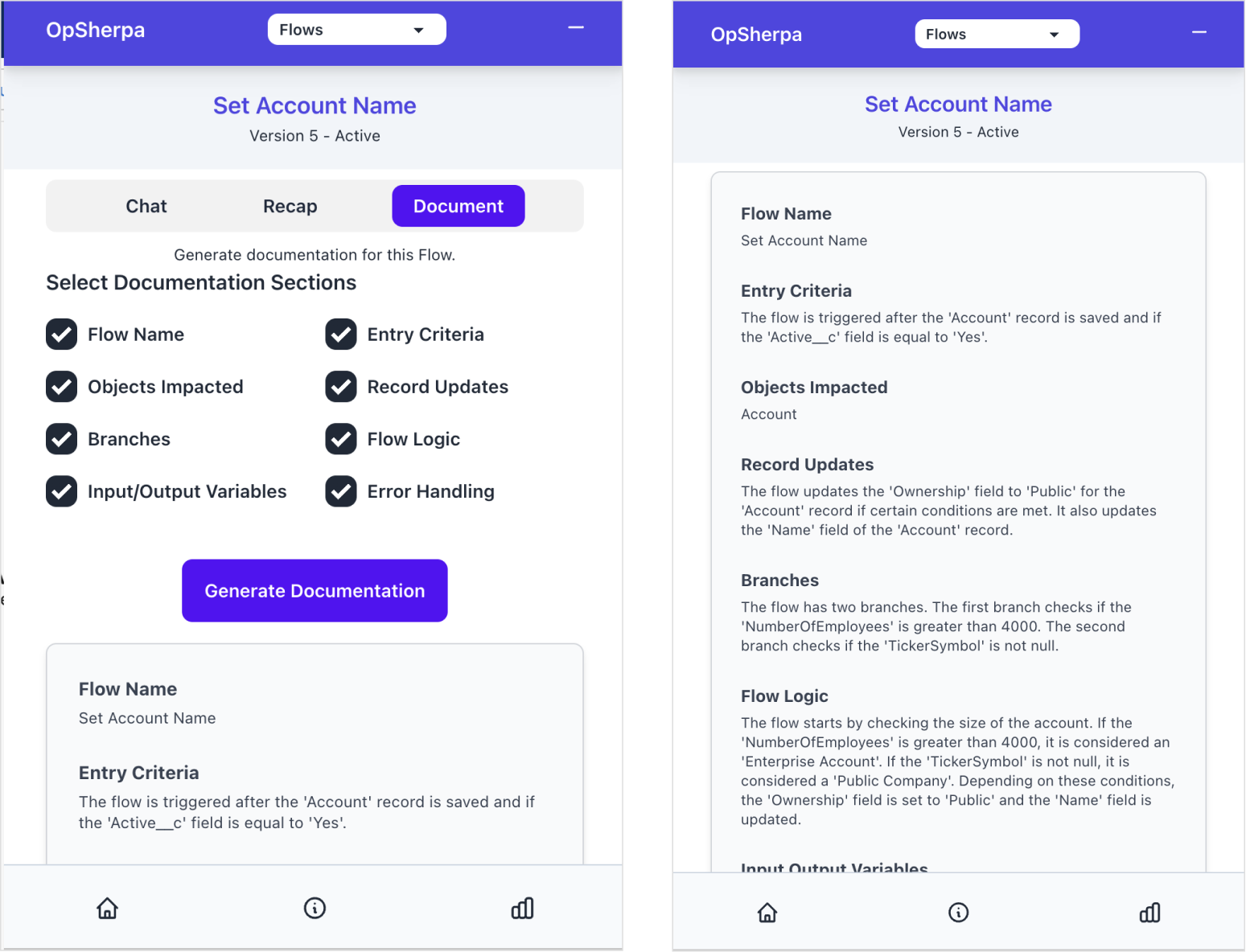
What's Next?
Embeddings and Retrival Augmented Generation
Currently, this copilot does not use vector DBs or Retrieval Augmented Generation. I suspect the performance and accuracy of the copilot will improve significantly with these features.
Embedding the components of the user's Salesforce instance will unlock additional functionality, such as universal search across components and Query Retrievers that can automatically route the request to the relevant component and retrieve its metadata.
Slack Integration
In its current state, the copilot is purely reactive; the user must open the Chrome extension and interact with it to get value.
An interesting form factor for the copilot would be a Slack integration that proactively posts recaps of changes to components and allows the user to interact with the copilot via Slack.
Proactive Agents with Platform Events
Salesforce platform events allow the instance to emit events to third-party apps, such as when a component has an error or when a component is deployed.
These events can be used to trigger an agent that will automatically parse the event and then take action, such as generating a recap or debugging an error and posting the result to Slack.
Open Source LLMs for Cheaper Inference
While costs have been very low developing this project, around $15 for 2 months of API usage, I'd like to explore using open source LLMs, such as the newly released LLama 2 to lower inference costs. In addition, deploying this copilot in an enterprise setting would likely require the use of open source or self-hosted LLMs to maintain user privacy
What do you think?
Would love to hear your thoughts on this project and how you think it could be improved. Feel free to reach out on Twitter or via email!